Etsy’s Financial Crimes team manually reviewed thousands of listings per month overwhelming agents and inflating operational cost
What is Apollo Flags?
Apollo is Etsy’s internal task management and workflow platform, designed to help teams handle member interactions, automate processes, and ensure quality assurance.
Problem Space
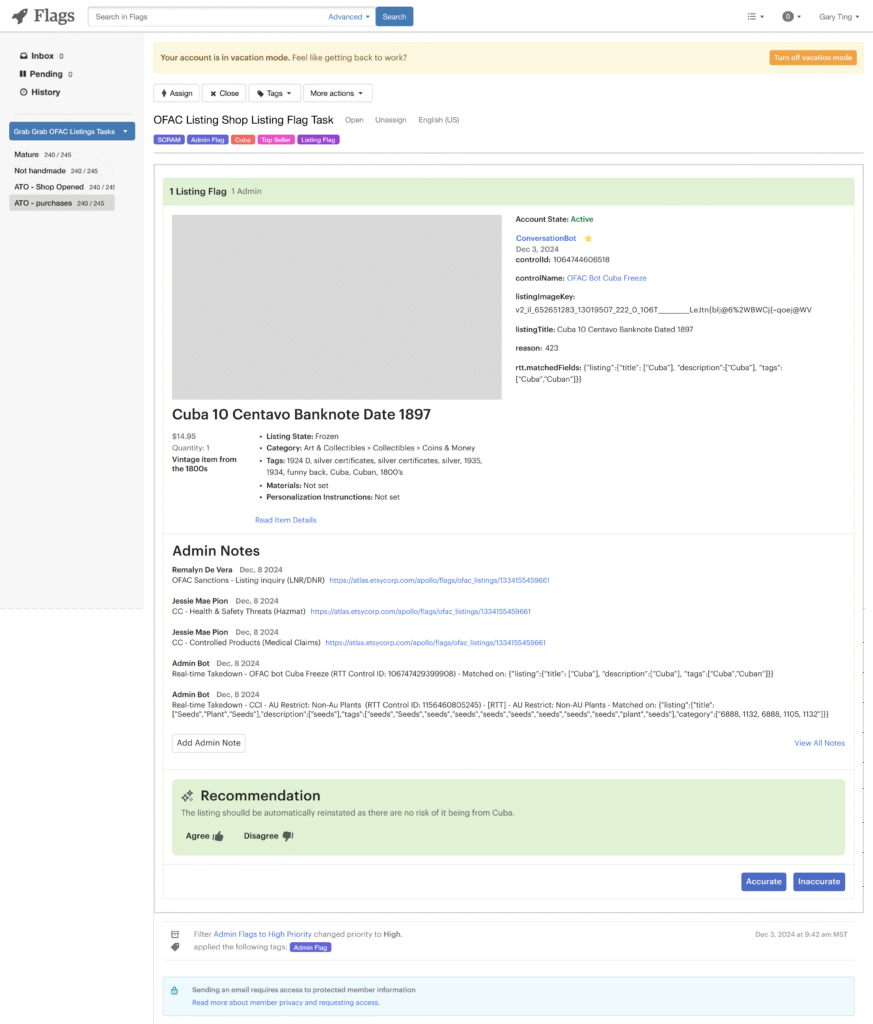
Etsy’s Financial Crimes team manually reviewed thousands of listings, per month, flagged by automated sanctions detection. The existing trigger generated roughly 5,000 false positives each month, overwhelming reviewers and inflating operational cost. LLM tools existed in isolation from Apollo, limiting usability and adoption.
Manual, expensive, error-prone listing reviews
Significant government fines for failure to enforce Foreign Assets laws
Agents were required to review listing and member information in multiple tools in order to arrive to an outcome in the Apollo queue
How might we integrate AI recommendations directly into agent workflows to help reviewers make faster, more accurate decisions—with fewer manual touch points and errors?
Opportunities
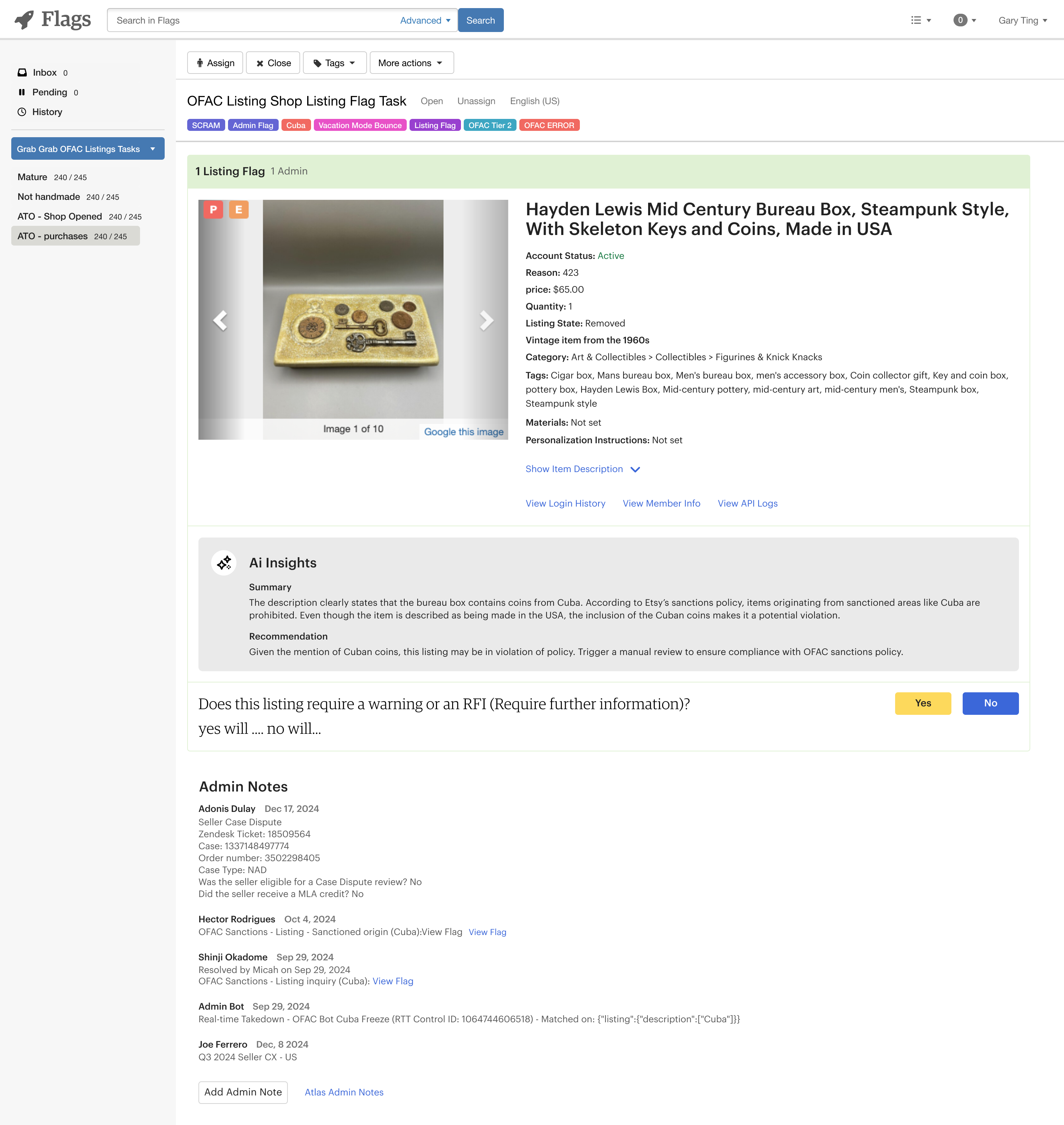
Integrate the LLM model’s summary, risk, and recommendation directly into the Apollo review screen
Make the AI recommendation clear, interpretable, and actionable
Reduce average handle time (AHT) and manual escalation rate
Increase agent trust and adoption of the LLM workflow
Constraints
No resources for a complete design overhaul
Integrating a LLM into Apollo required backend infrastructure changes, prompt logic and management, and custom UI behavior
Lack of trust for AI Integration as a tool
All designs were subject to legal review and compliance governance
High operational risk and visibility
Limited user pool for research and usability testing
My Role
As the Lead product designer for the Agent tooling team, I partnered with product, engineering, and compliance stakeholders to define and deliver the OFAC LLM experience within Apollo. My responsibilities included creating interactive prototypes, designing UI layouts, and conducting moderated usability studies to validate agent comprehension and trust in AI recommendations. I developed research scripts, question sets, and pilot studies, moderated sessions with internal agents, and synthesized findings into actionable design changes. Throughout the project, I worked closely with data scientists and agent management SMEs to translate complex compliance workflows into clear, interpretable interfaces that balanced regulatory precision with usability.
Process
Discovery
I began by auditing the existing OFAC review flow, mapping points of cognitive load and manual decision friction. Working with data scientists and the product manager, I redesigned the layout to surface AI context earlier, testing three layout variations:
Recommendation below the listing,
Recommendation first (above context),
Simplified layout removing redundant, supplemental data
To validate usability and comprehension, I moderated a usability study with five internal agents. I built interactive prototypes in Figma, developed the testing script and question set, and led moderated remote sessions capturing feedback and behavioral data.
Iterations & User Feedback
Each iteration was reviewed in weekly UX critiques with the internal support and tooling design team and produce teams, respectively. Design concepts were pushed into production and reviewed further with agents through moderated usability testing.
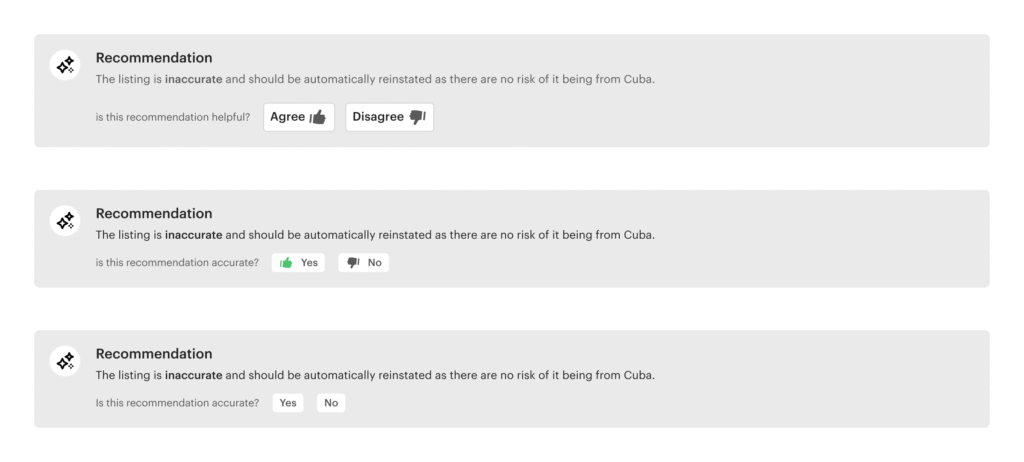
Early iterations included a feedback element asking agents whether the LLM’s recommendation was helpful. During testing, this phrasing received positive feedback in 97% of all sessions, indicating strong clarity and trust in the AI’s communication. Because the feature consistently scored high and offered limited new insight after validation, it was removed in later design iterations to streamline the interface and reduce redundancy.
Solution
Integrated AI panel in Apollo showing a concise summary, risk rationale, and recommendation
Region-specific prompts fine-tuned for accuracy
Inline decision workflow allowing agents to act on AI suggestions without switching tools
Conservative prompt logic designed to minimize false negatives
Results & Impact
72% reduction in weekly case volume
$390K annual cost savings in operational overhead.
Escalations reduced by 50%
QA accuracy 95%, with zero false negatives in production sampling.
Improved agent trust and adoption — feedback described the tool as “a game-changer” and “huge for time efficiency“
Learnings & Reflections
Integrating AI into workflows demands transparency and interpretability, agents must see why the model recommends an action
Early usability testing and prompt iteration were critical to adoption; trust was built through visible logic and consistent structure
Based on this project success, there was a missed opportunity for broader AI-assisted decision support across other other business use cases